



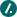


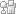

GFS является наиболее, наверное, известной распределенной файловой системой. Надежное масштабируемое хранение данных крайне необходимо для любого приложения, работающего с таким большим массивом данных, как все документы в интернете. GFS является основной платформой хранения информации в Google. GFS — большая распределенная файловая система, способная хранить и обрабатывать огромные объемы информации.
GFS строилась исходя из следующим критериев:
- Система строится из большого количества обыкновенного недорого оборудования, которое часто дает сбои. Должны существовать мониторинг сбоев, и возможность в случае отказа какого-либо оборудования восстановить функционирование системы.
- Система должна хранить много больших файлов. Как правило, несколько миллионов файлов, каждый от 100 Мб и больше. Также часто приходится иметь дело с многогигабайтными файлами, которые также должны эффективно храниться. Маленькие файлы тоже должны храниться, но для них не оптимизируется работа системы.
- Как правило, встречаются два вида чтения: чтение большого последовательного фрагмента данных и чтение маленького объема произвольных данных. При чтении большого потока данных обычным делом является запрос фрагмента размером в 1Мб и больше. Такие последовательные операции от одного клиента часто читают подряд идущие куски одного и того же файла. Чтение небольшого размера данных, как правило, имеет объем в несколько килобайт. Приложения, критические по времени исполнения, должны накопить определенное количество таких запросов и отсортировать их по смещению от начала файла. Это позволит избежать при чтении блужданий вида назад-вперед.
- Часто встречаются операции записи большого последовательного куска данных, который необходимо дописать в файл. Обычно, объемы данных для записи такого же порядка, что и для чтения. Записи небольших объемов, но в произвольные места файла, как правило, выполняются не эффективно.
- Система должна реализовывать строго очерченную семантику параллельной работы нескольких клиентов, в случае если они одновременно пытаются дописать данные в один и тот же файл. При этом может случиться так, что поступят одновременно сотни запросов на запись в один файл. Для того чтобы справится с этим, используется атомарность операций добавления данных в файл, с некоторой синхронизацией. То есть если поступит операция на чтение, то она будет выполняться, либо до очередной операции записи, либо после.
- Высокая пропускная способность является более предпочтительной, чем маленькая задержка. Так, большинство приложений в Google отдают предпочтение работе с большими объемами данных, на высокой скорости, а выполнение отдельно взятой операции чтения и записи, вообще говоря, может быть растянуто.
Файлы в GFS организованы иерархически, при помощи каталогов, как и в любой другой файловой системе, и идентифицируются своим путем. С файлами в GFS можно выполнять обычные операции: создание, удаление, открытие, закрытие, чтение и запись.
Более того, GFS поддерживает резервные копии, или снимки (snapshot). Можно создавать такие резервные копии для файлов или дерева директорий, причем с небольшими затратами.
Архитектура GFS
Рисунок взят из оригинальной статьи.
В системе существуют мастер-сервера и чанк-сервера, собственно, хранящие данные. Как правило, GFS кластер состоит из одной главной машины мастера (master) и множества машин, хранящих фрагменты файлов чанк-серверы (chunkservers). Клиенты имеют доступ ко всем этим машинам. Файлы в GFS разбиваются на куски — чанки (chunk, можно сказать фрагмент). Чанк имеет фиксированный размер, который может настраиваться. Каждый такой чанк имеет уникальный и глобальный 64 — битный ключ, который выдается мастером при создании чанка. Чанк-серверы хранят чанки, как обычные Linux файлы, на локальном жестком диске. Для надежности каждый чанк может реплицироваться на другие чанк-серверы. Обычно используются три реплики.
Мастер отвечает за работу с метаданными всей файловой системы. Метаданные включают в себя пространства имен, информацию о контроле доступа к данным, отображение файлов в чанки, и текущее положение чанков. Также мастер контролирует всю глобальную деятельность системы такую, как управление свободными чанками, сборка мусора (сбор более ненужных чанков) и перемещение чанков между чанк-серверами. Мастер постоянно обменивается сообщениями (HeartBeat messages) с чанк-серверами, чтобы отдать инструкции, и определить их состояние (узнать, живы ли еще).
Клиент взаимодействует с мастером только для выполнения операций, связанных с метаданными. Все операции с самими данными производятся напрямую с чанк-серверами. GFS — система не поддерживает POSIX API, так что разработчикам не пришлось связываться с VNode уровнем Linux.
Разработчики не используют кеширование данных, правда, клиенты кешируют метаданные. На чанк-серверах операционная система Linux и так кеширует наиболее используемые блоки в памяти. Вообще, отказ от кеширования позволяет не думать о проблеме валидности кеша (cache coherence).
Мастер
Использование одного мастера существенно упрощает архитектуру системы. Позволяет производить сложные перемещения чанков, организовывать репликации, используя глобальные данные. Казалось бы, что наличие только одного мастера должно являться узким местом системы, но это не так. Клиенты никогда не читают и не пишут данные через мастера. Вместо этого они спрашивают у мастера, с каким чанк-сервером они должны контактировать, а далее они общаются с чанк-серверами напрямую.
Рассмотрим, как происходит чтение данных клиентом. Сначала, зная размер чанка,
имя файла и смещение относительно начала файла, клиент определяет номер чанка внутри файла. Затем он шлет запрос мастеру, содержащий имя файла и номер чанка в этом файле. Мастер выдает чанк-серверы, по одному в каждой реплике, которые хранят нужный нам чанк. Также мастер выдает клиенту идентификатор чанка.
Затем клиент решает, какая из реплик ему нравится больше (как правило та, которая ближе), и шлет запрос, состоящий из чанка и смещения относительно начала чанка. Дальнейшее чтения данных, не требует вмешательства мастера. На практике, как правило, клиент в один запрос на чтение включает сразу несколько чанков, и мастер дает координаты каждого из чанков в одном ответе.
Размер чанка является важной характеристикой системы. Как правило, он устанавливается равным 64 мегабайт, что гораздо больше, чем размер блока в обычной файловой системе. Понятно, что если необходимо хранить много файлов, размеры которых меньше размера чанка, то будем расходоваться много лишней памяти. Но выбор такого большого размера чанка обусловлен задачами, которые приходится компании Google решать на своих кластерах. Как правило, что-то считать приходится для всех документов в интернете, и поэтому файлы в этих задачах очень большого размера.
Метаданные
Мастер хранит три важных вида метаданных: пространства имен файлов и чанков, отображение файла в чанки и положение реплик чанков. Все метаданные хранятся в памяти мастера. Так как метаданные хранятся в памяти, операции мастера выполняются быстро. Состояние дел в системе мастер узнает просто и эффективно. Он выполняется сканирование чанк-серверов в фоновом режиме. Эти периодические сканирования используются для сборки мусора, дополнительных репликаций, в случае обнаружения недоступного чанк-сервера и перемещение чанков, для балансировки нагрузки и свободного места на жестких дисках чанк-серверов.
Мастер отслеживает положение чанков. При старте чанк-сервера мастер запоминает его чанки. В процессе работы мастер контролирует все перемещения чанков и состояния чанк-серверов. Таким образом, он обладает всей информацией о положении каждого чанка.
Важная часть метаданных — это лог операций. Мастер хранит последовательность операций критических изменений метаданных. По этим отметкам в логе операций, определяется логическое время системы. Именно это логическое время определяет версии файлов и чанков.
Так как лог операций важная часть, то он должен надежно храниться, и все изменения в нем должны становиться видимыми для клиентов, только когда изменятся метаданные. Лог операций реплицируется на несколько удаленных машин, и система реагирует на клиентскую операцию, только после сохранения этого лога на диск мастера и диски удаленных машин.
Мастер восстанавливает состояние системы, исполняя лог операций. Лог операций сохраняет относительно небольшой размер, сохраняя только последние операции. В процессе работы мастер создает контрольные точки, когда размер лога превосходит некоторой величины, и восстановить систему можно только до ближайшей контрольной точки. Далее по логу можно заново воспроизвести некоторые операции, таким образом, система может откатываться до точки, которая находится между последней контрольной точкой и текущем временем.
Взаимодействия внутри системы
Выше была описана архитектура системы, которая минимизирует вмешательства мастера в выполнение операций. Теперь же рассмотрим, как взаимодействуют клиент, мастер и чанк-серверы для перемещения данных, выполнения атомарных операций записи, и создания резервной копии (snapshot).
Каждое изменение чанка должно дублироваться на всех репликах и изменять метаданные. В GFS мастер дает чанк во владение(lease) одному из серверов, хранящих этот чанк. Такой сервер называется первичной (primary) репликой. Остальные реплики объявляются вторичными (secondary). Первичная реплика собирает последовательные изменения чанка, и все реплики следуют этой последовательности, когда эти изменения происходят.
Механизм владения чанком устроен таким образом, чтобы минимизировать нагрузку на мастера. При выделении памяти сначала выжидается 60 секунд. А затем, если потребуется первичная реплика может запросить мастера на расширение этого интервала и, как правило, получает положительный ответ. В течение этого выжидаемого периода мастер может отменить изменения.
Рассмотрим подробно процесс записи данных. Он изображен по шагам на рисунке, при этом тонким линиям соответствуют потоки управления, а жирным потоки данных.
Этот рисунок также взят из оригинальной статьи.
- Клиент спрашивает мастера, какой из чанк-серверов владеет чанком, и где находится этот чанк в других репликах. Если необходимо, то мастер отдает чанк кому-то во владение.
- Мастер в ответ выдает первичную реплику, и остальные (вторичные) реплики. Клиент хранит эти данные для дальнейших действий. Теперь, общение с мастером клиенту может понадобиться только, если первичная реплика станет недоступной.
- Далее клиент отсылает данные во все реплики. Он может это делать в произвольном порядке. Каждый чанк-сервер будет их хранить в специальном буфере, пока они не понадобятся или не устареют.
- Когда все реплики примут эти данные, клиент посылает запрос на запись первичной реплике. В этом запросе содержатся идентификация данных, которые были посланы в шаге 3. Теперь первичная реплика устанавливает порядок, в котором должны выполняться все изменения, которые она получила, возможно от нескольких клиентов параллельно. И затем, выполняет эти изменения локально в этом определенном порядке.
- Первичная реплика пересылает запрос на запись всем вторичным репликам. Каждая вторичная реплика выполняет эти изменения в порядке, определенном первичной репликой.
- Вторичные реплики рапортуют об успешном выполнении этих операций.
- Первичная реплика шлет ответ клиенту. Любые ошибки, возникшие в какой-либо реплике, также отсылаются клиенту. Если ошибка возникла при записи в первичной реплике, то и запись во вторичные реплики не происходит, иначе запись произошла в первичной реплике, и подмножестве вторичных. В этом случае клиент обрабатывает ошибку и решает, что ему дальше с ней делать.
Из примера выше видно, что создатели разделили поток данных и поток управления. Если поток управления идет только в первичную реплику, то поток данных идет во все реплики. Это сделано, чтобы избежать создания узких мест в сети, а взамен широко использовать пропускную способность каждой машины. Так же, чтобы избежать узких мест и перегруженных связей, используется схема передачи ближайшему соседу по сетевой топологии. Допустим, что клиент передает данные чанк-серверам S1,..., S4. Клиент шлет ближайшему серверу данные, пусть S1. Он далее пересылает ближайшему серверу, пусть будет S2. Далее S2 пересылает их ближайшему S3 или S4, и так далее.
Также задержка минимизируется за счет использования конвейеризации пакетов передаваемых данных по TCP. То есть, как только чанк-сервер получил какую-то часть данных, он немедленно начинает их пересылать. Без сетевых заторов, идеальное время рассылки данных объемом B байт на R реплик будет B/T + RL, где T сетевая пропускная способность, а L — задержка при пересылке одного байта между двумя машинами.
GFS поддерживает такую операцию, как атомарное добавление данных в файл. Обычно, при записи каких-то данных в файл, мы указываем эти данные и смещение. Если несколько клиентов производят подобную операцию, то эти операции нельзя переставлять местами (это может привести к некорректной работе). Если же мы просто хотим дописать данные в файл, то в этом случае мы указываем только сами данные. GFS добавит их атомарной операцией. Вообще говоря, если операция не выполнилась на одной из вторичных реплик, то GFS, вернет ошибку, а данные будут на разных репликах различны.
Еще одна интересная вещь в GFS — это резервные копии (еще можно сказать мгновенный снимок) файла или дерева директорий, которые создаются почти мгновенно, при этом, почти не прерывая выполняющиеся операции в системе. Это получается за счет технологии похожей на сopy on write. Пользователи используют эту возможность для создания веток данных или как промежуточную точку, для начала каких-то экспериментов.
Операции, выполняемые мастером
Мастер важное звено в системе. Он управляет репликациями чанков: принимает решения о размещении, создает новые чанки, а также координирует различную деятельность внутри системы для сохранения чанков полностью реплицированными, балансировки нагрузки на чанк-серверы и сборки неиспользуемых ресурсов.
В отличие от большинства файловых систем GFS не хранит состав файлов в директории. GFS логически представляет пространство имен, как таблицу, которая отображает каждый путь в метаданные. Такая таблица может эффективно храниться в памяти в виде бора (словаря этих самых путей). Каждая вершина в этом дереве (соответствует либо абсолютному пути к файлу, либо к директории) имеет соответствующие данные для блокировки чтения и записи(read write lock). Каждое операция мастера требует установления некоторых блокировок. В этом месте в системе используются блокировки чтения-записи. Обычно, если операция работает с /d1/d2/.../dn/leaf, то она устанавливает блокировки на чтение на /d1, /d1/d2, ..., d1/d2/.../dn и блокировку, либо на чтение, либо на запись на d1/d2/.../dn/leaf. При этом leaf может быть как директорией, так и файлом.
Покажем на примере, как механизм блокировок может предотвратить создание файла /home/user/foo во время резервного копирования /home/user в /save/user. Операция резервного копирования устанавливает блокировки на чтение на /home и /save, а так же блокировки на запись на /home/user и /save/user. Операция создания файла требует блокировки на чтение /home и /home/user, а также блокировки на запись на /home/user/foo. Таким образом, вторая операция не начнет выполняться, пока не закончит выполнение первая, так как есть конфликтующая блокировка на /home/user. При создании файла не требуется блокировка на запись родительской директории, достаточно блокировки на чтение, которая предотвращает удаление этой директории.
Кластеры GFS, являются сильно распределенными и многоуровневыми. Обычно, такой кластер имеет сотни чанк-серверов, расположенных на разных стойках. Эти сервера, вообще говоря, доступны для большого количества клиентов, расположенных в той же или другой стойке. Соединения между двумя машинами из различных стоек может проходить через один или несколько свитчей. Многоуровневое распределение представляет очень сложную задачу надежного, масштабируемого и доступного распространения данных.
Политика расположения реплик старается удовлетворить следующим свойствам: максимизация надежности и доступности данных и максимизация использование сетевой пропускной способности. Реплики должны быть расположены не только на разных дисках или разных машинах, но и более того на разных стойках. Это гарантирует, что чанк доступен, даже если целая стойка повреждена или отключена от сети. При таком расположении чтение занимает время приблизительно равное пропускной способности сети, зато поток данных при записи должен пройти через различные стойки.
Когда мастер создает чанк, он выбирает где разместить реплику. Он исходит из нескольких факторов:
- Желательно поместить новую реплику на чанк-сервер с наименьшей средней загруженностью дисков. Это будет со временем выравнивать загруженность дисков на различных серверах.
- Желательно ограничить число новых создаваемых чанков на каждом чанк-сервере. Несмотря на то, что создание чанка сама по себе быстрая операция, она подразумевает последующую запись данных в этот чанк, что уже является тяжелой операцией, и это может привести к разбалансировке объема трафика данных на разные части системы.
- Как сказано выше, желательно распределить чанки среди разных стоек.
Как только число реплик падает ниже устанавливаемой пользователем величины, мастер снова реплицирует чанк. Это может случиться по нескольким причинам: чанк-сервер стал недоступным, один из дисков вышел из строя или увеличена величина, задающая число реплик. Каждому чанку, который должен реплицироваться, устанавливается приоритет, который тоже зависит от нескольких факторов. Во-первых, приоритет выше у того чанка, который имеет наименьшее число реплик. Во-вторых, чтобы увеличить надежность выполнения приложений, увеличивается приоритет у чанков, которые блокируют прогресс в работе клиента
Мастер выбирает чанк с наибольшим приоритетом и копирует его, отдавая инструкцию одному из чанк-серверов, скопировать его с доступной реплики. Новая реплика располагается, исходя из тех же причин, что и при создании.
Во время работы мастер постоянно балансирует реплики. В зависимости от распределения реплик в системе, он перемещает реплику для выравнивания загруженности дисков и балансировки нагрузки. Также мастер должен решать, какую из реплик стоит удалить. Как правило, удаляется реплика, которая находится на чанк-сервере с наименьшим свободным местом на жестких дисках.
Еще одна важная функция, лежащая на мастере — это сборка мусора. При удалении файла, GFS не требует мгновенного возвращения освободившегося дискового пространства. Он делает это во время регулярной сборки мусора, которая происходит как на уровне чанков, так и на уровне файлов. Авторы считают, что такой подход делает систему более простой и надежной.
При удалении файла приложением, мастер запоминает в логах этот факт, как и многие другие. Тем не менее, вместо требования немедленного восстановления освободившихся ресурсов, файл просто переименовывается, причем в имя файла добавляется время удаления, и он становится невидимым пользователю. А мастер, во время регулярного сканирования пространства имен файловой системы, реально удаляет все такие скрытые файлы, которые были удалены пользователем более трех дней назад (этот интервал настраивается). А до этого момента файл продолжает находиться в системе, как скрытый, и он может быть прочитан или переименован обратно для восстановления. Когда скрытый файл удаляется мастером, то информация о нем удаляется также из метаданных, а все чанки этого файла отцепляются от него.
Мастер помимо регулярного сканирования пространства имен файлов делает аналогичное сканирование пространства имен чанков. Мастер определяет чанки, которые отсоединены от файла, удаляет их из метаданных и во время регулярных связей с чанк-серверами передает им сигнал о возможности удаления всех реплик, содержащих заданный чанк. У такого подхода к сборке мусора много преимуществ, при одном недостатке: если место в системе заканчивается, а отложенное удаление увеличивает неиспользуемое место, до момента самого физического удаления. Зато есть возможность восстановления удаленных данных, возможность гибкой балансировки нагрузки при удалении и возможность восстановления системы, в случае каких-то сбоев.
Устойчивость к сбоям и диагностика ошибок
Авторы системы считают одной из наиболее сложных проблем частые сбои работы компонентов системы. Количество и качество компонентов делают эти сбои не просто исключением, а скорее нормой. Сбой компонента может быть вызван недоступностью этого компонента или, что хуже, наличием испорченных данных. GFS поддерживает систему в рабочем виде при помощи двух простых стратегий: быстрое восстановление и репликации.
Быстрое восстановление — это, фактически, перезагрузка машины. При этом время запуска очень маленькое, что приводит к маленькой заминке, а затем работа продолжается штатно. Про репликации чанков уже говорилось выше. Мастер реплицирует чанк, если одна из реплик стала недоступной, либо повредились данные, содержащие реплику чанка. Поврежденные чанки определяется при помощи вычисления контрольных сумм.
Еще один вид репликаций в системе, про который мало было сказано — это репликация мастера. Реплицируется лог операций и контрольные точки (checkpoints). Каждое изменение файлов в системе происходит только после записи лога операций на диски мастером, и диски машин, на которые лог реплицируется. В случае небольших неполадок мастер может перезагрузиться. В случае проблем с жестким диском или другой жизненно важной инфраструктурой мастера, GFS стартует нового мастера, на одной из машин, куда реплицировались данные мастера. Клиенты обращаются к мастеру по DNS, который может быть переназначен новой машине. Новый мастер является тенью старого, а не точной копией. Поэтому у него есть доступ к файлам только для чтения. То есть он не становится полноценным мастером, а лишь поддерживает лог операций и другие структуры мастера.
Важной частью системы является возможность поддерживать целостность данных. Обычный GFS кластер состоит из сотен машин, на которых расположены тысячи жестких дисков, и эти диски при работе с завидным постоянством выходят из строя, что приводит к порче данных. Система может восстановить данные с помощью репликаций, но для этого необходимо понять испортились ли данные. Простое сравнение различных реплик на разных чанк-серверах является неэффективным. Более того, может происходить несогласованность данных между различными репликами, ведущая к различию данных. Поэтому каждый чанк-сервер должен самостоятельно определять целостность данных.
Каждый чанк разбивается на блоки длиной 64 Кбайт. Каждому такому блоку соответствует 32-битная контрольная сумма. Как и другие метаданные эти суммы хранятся в памяти, регулярно сохраняются в лог, отдельно от данных пользователя.
Перед тем как считать данные чанк-сервер проверяет контрольные суммы блоков чанка, которые пересекаются с затребованными данными пользователем или другим чанк-сервером. То есть чанк-сервер не распространяет испорченные данные. В случае несовпадения контрольных сумм, чанк-сервер возвращает ошибку машине, подавшей запрос, и рапортует о ней мастеру. Пользователь может считать данные из другой реплики, а мастер создает еще одну копию из данных другой реплики. После этого мастер дает инструкцию этому чанк-серверу об удалении этой испорченной реплики.
При добавлении новых данных, верификация контрольных сумм не происходит, а для блоков записывается новые контрольные суммы. В случае если диск испорчен, то это определится при попытке чтения этих данных. При записи чанк-сервер сравнивает только первый и последний блоки, пересекающиеся с границами, в которые происходит запись, поскольку часть данных на этих блоках не перезаписывается и необходимо проверить их целостность.




